Kiểm Định Phương Sai Sai Số Không Đồng Nhất trong SPSS
HЖ°б»›ng Dбє«n Chi Tiбєїt Tб»« LГЅ Thuyбєїt Д‘бєїn BГЎo CГЎo Hб»Ќc Thuбєt
ChuyГЄn mục: PhЖ°ЖЎng phГЎp nghiГЄn cб»©u | Tб»« khГіa: heteroskedasticity, Breusch-Pagan, White test, HC3 robust standard errors, SPSS, hб»“i quy tuyбєїn tГnh
Khi chбєЎy hб»“i quy tuyбєїn
tГnh (OLS), mб»™t trong nhб»Їng giбєЈ Д‘б»‹nh quan trб»Ќng nhất lГ phЖ°ЖЎng sai của sai sб»‘
không đổi (homoskedasticity). Nếu giả định nà y bị vi phạm — tức là có hiện
tượng phương sai sai số không đồng nhất (heteroskedasticity) — thì các ước
lЖ°б»Јng hệ sб»‘ hб»“i quy vбє«n khГґng chệch, nhЖ°ng sai sб»‘ chuбє©n (SE), giГЎ trб»‹ t, F vГ
p-value sбєЅ khГґng cГІn chГnh xГЎc, dбє«n Д‘бєїn kбєїt luбєn thб»‘ng kГЄ sai.
BГ i viбєїt nГ y hЖ°б»›ng dбє«n
toà n diện cách phát hiện và xỠlý heteroskedasticity trong SPSS, bao gồm lý
thuyбєїt cГЎc kiб»ѓm Д‘б»‹nh, thao tГЎc bбє±ng menu vГ syntax, Д‘б»Ќc kбєїt quбєЈ, vГ viбєїt bГЎo
cГЎo hб»Ќc thuбєt. CГўu trГch dбє«n chuбє©n mб»±c Д‘Ж°б»Јc nhiб»Ѓu bГ i bГЎo quб»‘c tбєї sб» dụng lГ :
|
"Nghiên cứu kiểm tra hiện tượng phương sai sai
số không đồng nhất bằng kiểm định Breusch–Pagan và White (Breusch &
Pagan, 1979; White, 1980). Khi phát hiện heteroskedasticity, nghiên cứu sỠdụng
sai sб»‘ chuбє©n hiệu chỉnh robust theo HC3 Д‘б»ѓ Д‘бєЈm bбєЈo suy luбєn thб»‘ng kГЄ Д‘ГЎng tin
cбєy hЖЎn (MacKinnon & White, 1985)." |
1. Heteroskedasticity là gì và tại sao quan trọng?
1.1. Дђб»‹nh nghД©a
Trong mô hình hồi quy
tuyбєїn tГnh y = XОІ + Оµ, giбєЈ Д‘б»‹nh
homoskedasticity Д‘ГІi hб»Џi Var(Оµi) = ПѓВІ
cho mọi quan sát i. Heteroskedasticity xảy ra khi phương sai của sai số
thay Д‘б»•i theo cГЎc giГЎ trб»‹ của biбєїn Д‘б»™c lбєp — tб»©c lГ Var(Оµi) = ПѓВІi vГ ПѓВІi khГґng hбє±ng sб»‘.
Hбєu quбєЈ kб»№ thuбєt quan
trọng nhất được trình bà y trong Breusch & Pagan (1979) và White (1980): ước
lượng OLS vẫn không chệch (unbiased) và nhất quán (consistent), nhưng không còn
hiệu quả (efficient). Nghiêm trọng hơn, sai số chuẩn OLS thông thường bị ước
lượng sai — thường là quá nhỏ — dẫn đến t-statistic và F-statistic bị thổi phồng,
lГ m tДѓng xГЎc suất mбєЇc lб»—i LoбєЎi I (kбєїt luбєn cГі ГЅ nghД©a khi thб»±c tбєї khГґng cГі).
1.2. NguyГЄn nhГўn phб»• biбєїn
PROFIT88
•
Dб»Ї
liệu chéo (cross-sectional): công ty lớn có biến động doanh thu lớn hơn công ty
nhб»Џ
•
Dб»Ї
liệu chuỗi thời gian: biến động tăng theo thời gian do tăng trưởng kinh tế
•
MГґ
hình đặc tả sai: bỏ sót biến quan trọng hoặc dạng hà m không phù hợp
• Outliers: một và i giá trị cực đoan có thể tạo ra phương sai không đều
1.3. TбєЎi sao cбє§n bГЎo cГЎo vГ xб» lГЅ?
CГЎc tбєЎp chГ quб»‘c tбєї
hГ ng Д‘бє§u trong quбєЈn trб»‹, marketing, kinh tбєї vГ khoa hб»Ќc xГЈ hб»™i ngГ y cГ ng yГЄu cбє§u
tГЎc giбєЈ bГЎo cГЎo kiб»ѓm Д‘б»‹nh heteroskedasticity. Theo MacKinnon & White
(1985), ngay cả khi không phát hiện được heteroskedasticity bằng các kiểm định
chГnh thб»©c, vбє«n nГЄn cГўn nhбєЇc sб» dụng robust standard errors vГ¬ cГЎc kiб»ѓm
Д‘б»‹nh cГі thб»ѓ thiбєїu power б»џ mбє«u nhб»Џ.
2.
CГЎc kiб»ѓm Д‘б»‹nh heteroskedasticity: LГЅ thuyбєїt vГ so sГЎnh
2.1. Kiểm định Breusch–Pagan (1979)
Nguб»“n gб»‘c: Breusch & Pagan
(1979), Econometrica, Vol. 47, pp. 1287–1294.
Breusch–Pagan test dựa
trГЄn khuГґn khб»• kiб»ѓm Д‘б»‹nh Lagrange Multiplier (LM). Гќ tЖ°б»џng cб»‘t lГµi lГ : nбєїu cГі
heteroskedasticity, bình phương phần dư OLS (û²) sẽ có mối quan hệ có ý nghĩa với
các biến dự báo. Quy trình gồm ba bước:
1.
Bước 1: Chạy hồi quy OLS gốc, lấy phần dư û
2.
BЖ°б»›c 2: TГnh gt = û²/ПѓМ‚ВІ
(chuẩn hóa bình phương phần dư)
3.
BЖ°б»›c 3: Hб»“i quy gt theo cГЎc biбєїn dб»± bГЎo. Thб»‘ng kГЄ LM =
ВЅ Г— ESS (explained sum of squares) ~ П‡ВІ(p-1)
|
Дђбє·c Д‘iб»ѓm |
Chi tiбєїt |
|
GiбєЈ
thuyбєїt H0 |
PhЖ°ЖЎng
sai sai số đồng nhất (homoskedasticity) |
|
PhГўn
phб»‘i thб»‘ng kГЄ |
П‡ВІ vб»›i bбєc tб»± do = sб»‘
biбєїn dб»± bГЎo |
|
Kбєїt
luбєn khi |
Sig.
< 0.05 в†’ bГЎc bб»Џ H0 в†’ cГі heteroskedasticity |
|
Дђбє·c
Д‘iб»ѓm |
NhбєЎy
vб»›i dбєЎng heteroskedasticity tuyбєїn tГnh; giбєЈ Д‘б»‹nh normality của sai sб»‘ |
|
Trong
SPSS 29 |
Lệnh
/PRINT BP trong UNIANOVA |
2.2. Kiб»ѓm Д‘б»‹nh White (1980)
Nguб»“n gб»‘c: White (1980), Econometrica,
Vol. 48, pp. 817–838.
White test tб»•ng quГЎt
hơn Breusch–Pagan. Nó không giả định dạng cụ thể của heteroskedasticity và cũng
là kiểm định chung về sự phù hợp của đặc tả mô hình. Quy trình hồi quy phụ đưa
û² vГ o lГ m biбєїn phụ thuб»™c, vб»›i cГЎc biбєїn Д‘б»™c lбєp bao gб»“m: tất cбєЈ biбєїn gб»‘c, bГ¬nh
phЖ°ЖЎng của chГєng, vГ tГch chГ©o giб»Їa chГєng.
|
Дђбє·c Д‘iб»ѓm |
Chi tiбєїt |
|
GiбєЈ
thuyбєїt H0 |
PhЖ°ЖЎng
sai sai sб»‘ khГґng phụ thuб»™c vГ o cГЎc biбєїn Д‘б»™c lбєp |
|
PhГўn
phб»‘i thб»‘ng kГЄ |
nRВІ
~ П‡ВІ vб»›i bбєc tб»± do = K(K+1)/2 (K = sб»‘ biбєїn gб»‘c) |
|
Kбєїt
luбєn khi |
Sig.
< 0.05 в†’ cГі heteroskedasticity hoбє·c Д‘бє·c tбєЈ sai |
|
Дђбє·c
Д‘iб»ѓm |
KhГґng
cần giả định normality; phát hiện được nhiều dạng heteroskedasticity |
|
ЖЇu
Д‘iб»ѓm |
CбєЈ
MacKinnon & White (1985) Д‘б»Ѓu khuyбєїn nghб»‹ dГ№ng White test |
|
Trong
SPSS 29 |
Lệnh
/PRINT WHITE trong UNIANOVA |
2.3. Modified Breusch–Pagan và F-test
SPSS 29 cũng cung cấp
hai biбєїn thб»ѓ bб»• sung:
•
Modified Breusch–Pagan: Phiên bản hiệu chỉnh theo Koenker
(1981), Гt nhбєЎy cбєЈm hЖЎn vб»›i giбєЈ Д‘б»‹nh vб»Ѓ phГўn phб»‘i sai sб»‘
• F-test for heteroskedasticity: Kiểm định dạng F thay vì χ², thường cho kết quả tương tự BP nhưng với phân phối khác
2.4. So sГЎnh tб»•ng thб»ѓ cГЎc kiб»ѓm Д‘б»‹nh
|
Kiб»ѓm Д‘б»‹nh |
GiбєЈ Д‘б»‹nh sai sб»‘ |
Dạng heteroskedasticity phát hiện |
Bбєc tб»± do SPSS |
|
Breusch–Pagan |
Gбє§n
chuбє©n |
Tuyбєїn
tГnh theo biбєїn dб»± bГЎo |
=
sб»‘ biбєїn Д‘б»™c lбєp |
|
Modified
BP |
Linh
hoбєЎt hЖЎn |
Tuyбєїn
tГnh, Гt cбє§n normality |
=
sб»‘ biбєїn Д‘б»™c lбєp |
|
White
test |
KhГґng
cбє§n chuбє©n |
Bất
kб»і, kб»ѓ cбєЈ phi tuyбєїn |
=
K(K+1)/2 |
|
F-test |
Gбє§n
chuбє©n |
Tuyбєїn
tГnh |
df1=1,
df2=n-k-1 |
|
Khuyбєїn nghб»‹ thб»±c tiб»…n: NГЄn bГЎo cГЎo Гt nhất hai kiб»ѓm Д‘б»‹nh (thЖ°б»ќng lГ
Breusch–Pagan vГ White). Nбєїu cбєЈ hai Д‘б»Ѓu cГі ГЅ nghД©a, kбєїt luбєn vб»Ѓ
heteroskedasticity sбєЅ mбєЎnh hЖЎn. |
3.
HC3 Robust Standard Errors: GiбєЈi phГЎp khi cГі heteroskedasticity
3.1. TбєЎi sao cбє§n robust standard errors?
Khi phát hiện
heteroskedasticity, cГі hai hЖ°б»›ng xб» lГЅ chГnh: (1) biбєїn Д‘б»•i dб»Ї liệu (Weighted
Least Squares), hoặc (2) giữ nguyên ước lượng OLS nhưng sỠdụng sai số chuẩn
hiệu chỉnh (heteroskedasticity-consistent standard errors). Hướng thứ hai
được ưa chuộng hơn trong thực tiễn nghiên cứu vì đơn giản và không yêu cầu biết
dбєЎng heteroskedasticity.
3.2. CГЎc phiГЄn bбєЈn HC (tб»« HC0 Д‘бєїn HC4)
White (1980) đề xuất ước
lượng gốc HC0. MacKinnon & White (1985) — trong bà i báo gốc "Some
Heteroskedasticity-Consistent Covariance Matrix Estimators with Improved Finite
Sample Properties" — so sánh hiệu năng của các phiên bản HC trong mẫu
nhб»Џ:
|
PhiГЄn bбєЈn |
Công thức điều chỉnh |
Дђбє·c Д‘iб»ѓm |
Khuyбєїn nghб»‹ |
|
HC0
(White) |
û²ᵢ |
Gб»‘c,
cГі thб»ѓ cГі bias б»џ mбє«u nhб»Џ |
TrГЎnh
khi n nhб»Џ |
|
HC1 |
n/(n–k)
× û²ᵢ |
Дђiб»Ѓu
chỉnh bбєc tб»± do Д‘ЖЎn giбєЈn |
Tб»‘t
hЖЎn HC0 |
|
HC2 |
û²ᵢ/(1–hᵢᵢ) |
Дђiб»Ѓu
chỉnh theo leverage hᵢᵢ |
Tб»‘t
trong nhiều tình huống |
|
HC3
(Jackknife) |
û²ᵢ/(1–hᵢᵢ)² |
Дђiб»Ѓu
chỉnh mбєЎnh hЖЎn, Гt bias nhất |
вњ“ Khuyбєїn
nghị cao nhất |
|
HC4 |
û²ᵢ/(1–hᵢᵢ)^δᵢ |
Дђiб»Ѓu
chỉnh thêm cho outliers mạnh |
Cho
dữ liệu có leverage cao |
Trong Д‘Гі hбµўбµў lГ phбє§n tб» Д‘Ж°б»ќng chГ©o
thứ i của hat matrix H = X(X'X)⁻¹X'.
MacKinnon & White (1985) kбєїt luбєn: HC3 luГґn cho hiệu nДѓng tб»‘t nhất trong
tất cả các thực nghiệm mô phỏng, kể cả khi mẫu nhỏ và mức
heteroskedasticity cao. SPSS 29 mặc định dùng HC3 trong lệnh /ROBUST=HC3.
|
TrГch dбє«n chuбє©n cho HC3: MacKinnon, J.G., & White, H. (1985). Some
heteroskedasticity-consistent covariance matrix estimators with improved
finite sample properties. Journal of Econometrics, 29(3), 305–325. |
4.
Thực hiện trong SPSS: Hướng dẫn từng bước
4.1. Cách A — Kiểm tra sơ bộ bằng đồ thị phần dư
TrЖ°б»›c khi chбєЎy kiб»ѓm Д‘б»‹nh
chГnh thб»©c, nГЄn xem xГ©t trб»±c quan bбє±ng scatterplot phбє§n dЖ° chuбє©n hГіa (ZRESID)
theo giГЎ trб»‹ dб»± Д‘oГЎn chuбє©n hГіa (ZPRED).
Thao tГЎc menu:
1.
Analyze в†’ Regression в†’ Linear в†’ Д‘Ж°a
biбєїn vГ o
2.
Bấm Save в†’ tГch Standardized
Predicted Values (ZPRED) vГ Standardized Residuals
(ZRESID)
3.
Graphs в†’ Legacy Dialogs в†’ Scatter/Dot в†’ Simple Scatter в†’ X: ZPRED, Y: ZRESID
CГЎch Д‘б»Ќc biб»ѓu Д‘б»“: Nбєїu Д‘iб»ѓm phГўn tГЎn Д‘б»Ѓu
xung quanh đường y=0 và độ rộng không đổi theo trục X: không có dấu hiệu rõ
rà ng. Nếu có hình phễu (fan shape) hoặc hình nón mở rộng: nghi ngờ có
heteroskedasticity.
|
LЖ°u ГЅ: PhЖ°ЖЎng
phГЎp Д‘б»“ thб»‹ chỉ mang tГnh Д‘б»‹nh tГnh, khГґng phбєЈi kiб»ѓm Д‘б»‹nh thб»‘ng kГЄ chГnh thб»©c.
Luôn cần bổ sung kiểm định Breusch–Pagan hoặc White. |
4.2. CГЎch B — Kiб»ѓm Д‘б»‹nh chГnh thб»©c trong SPSS 29 (BбєЎn Д‘б»Ќc lЖ°u ГЅ, cГЎc bбєЈn SPSS trЖ°б»›c 2024 sбєЅ khГґng cГі test nГ y)
Khi nà o dùng: Khi mô hình có 1 biến
phụ thuб»™c liГЄn tục vГ cГЎc biбєїn Д‘б»™c lбєp liГЄn tục (hoбє·c biбєїn giбєЈ), muб»‘n Д‘б»“ng thб»ќi
kiểm định heteroskedasticity và lấy kết quả với robust SE HC3.
Thao tГЎc menu tб»«ng bЖ°б»›c:
1.
Analyze в†’ General Linear Model в†’ Univariate
2.
Dependent Variable: đưa biến phụ thuộc và o (và dụ: WOM_)
3.
Covariate(s): Д‘Ж°a cГЎc biбєїn Д‘б»™c lбєp liГЄn tục vГ o (vГ dụ: BP_,
PDS_)
4.
Bấm Model → Custom → đưa BP_, PDS_ và o
model
5.
Bấm Options в†’ tГch Descriptive
Statistics như hình bên dưới
6.
Bấm OK

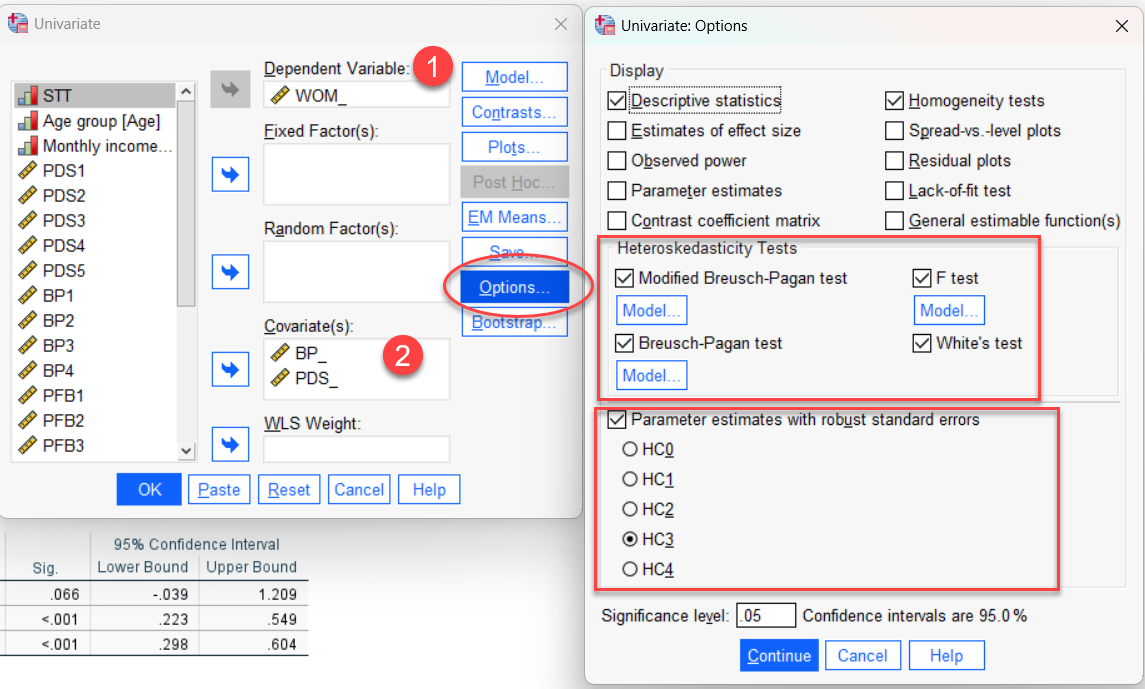
5.
Đọc và diễn giải kết quả SPSS — Và dụ thực tế
Dưới đây là và dụ thực
tế từ nghiên cứu với biến phụ thuộc WOM_ (Word-of-Mouth) và hai biến độc
lбєp BP_ (Brand Prestige) vГ PDS_ (Perceived Dependability &
Service), N = 270.
5.1. BбєЈng kiб»ѓm Д‘б»‹nh heteroskedasticity
SPSS in ra bб»‘n bбєЈng kiб»ѓm
Д‘б»‹nh. DЖ°б»›i Д‘Гўy lГ cГЎch Д‘б»Ќc tб»«ng bбєЈng:
|
Kiб»ѓm Д‘б»‹nh |
Thб»‘ng kГЄ |
df |
Sig. |
Kбєїt luбєn |
|
White
Test |
П‡ВІ = 45.222 |
5 |
<
.001 |
CГі
heteroskedasticity |
|
Modified
Breusch-Pagan |
П‡ВІ = 36.217 |
1 |
<
.001 |
CГі
heteroskedasticity |
|
Breusch-Pagan |
П‡ВІ = 56.743 |
1 |
<
.001 |
CГі
heteroskedasticity |
|
F
Test |
F
= 41.518 |
df1=1,
df2=268 |
<
.001 |
CГі
heteroskedasticity |
Diễn giải: Tất cả bốn kiểm định đều
có p < .001, cho thấy giả định phương sai đồng nhất bị vi phạm một cách rõ
rà ng. Kết quả nhất quán giữa các kiểm định (cả BP và White đều bác bỏ H0) tăng
cЖ°б»ќng Д‘б»™ tin cбєy của kбєїt luбєn.
|
ChГє ГЅ khi Д‘б»Ќc footnote SPSS: Mб»—i bбєЈng cГі ghi chГє (a, b, c) giбєЈi thГch biбєїn phụ
thuộc và mô hình được sỠdụng. Dòng 'c' cho biết White test dùng bình phương
vГ tГch chГ©o của cГЎc biбєїn dб»± bГЎo (BP_ * BP_, BP_ * PDS_, PDS_ * PDS_), Д‘Гєng vб»›i
lГЅ thuyбєїt White (1980). |
5.2. Bảng Tests of Between-Subjects Effects (mô hình OLS gốc)
|
Nguб»“n |
Type III SS |
df |
Mean Square |
F |
Sig. |
|
Corrected
Model |
126.097 |
2 |
63.048 |
120.424 |
<
.001 |
|
Intercept |
3.775 |
1 |
3.775 |
7.210 |
.008 |
|
BP_ |
25.263 |
1 |
25.263 |
48.253 |
<
.001 |
|
PDS_ |
35.470 |
1 |
35.470 |
67.749 |
<
.001 |
|
Error |
139.789 |
267 |
.524 |
|
|
|
Total |
4357.000 |
270 |
|
|
|
|
Corrected
Total |
265.885 |
269 |
|
|
|
|
Ghi chГє: RВІ =
.474 (Adjusted RВІ = .470). MГґ hГ¬nh giбєЈi thГch Д‘Ж°б»Јc 47.4% biбєїn thiГЄn của WOM_.
TUYỆT Дђб»ђI KHГ”NG dГ№ng bбєЈng nГ y Д‘б»ѓ kбєїt luбєn vб»Ѓ ГЅ nghД©a của BP_ vГ PDS_ vГ¬ SE Д‘ГЈ
bб»‹ sai do heteroskedasticity. Chuyб»ѓn sang bбєЈng HC3. |
5.3. BбєЈng Parameter Estimates with Robust Standard Errors
(HC3) — BбєЈng chГnh Д‘б»ѓ diб»…n giбєЈi
|
Tham sб»‘ |
B |
Robust SE (HC3) |
t |
Sig. |
95% CI (Lower) |
95% CI (Upper) |
|
Intercept |
0.585 |
0.317 |
1.847 |
.066 |
в€’0.039 |
1.209 |
|
BP_ |
0.386 |
0.083 |
4.672 |
< .001 |
0.223 |
0.549 |
|
PDS_ |
0.451 |
0.078 |
5.806 |
< .001 |
0.298 |
0.604 |
Footnote: a. HC3
method.
|
Đây là bảng quan trọng nhất để diễn giải: Vì có heteroskedasticity, SE trong bảng OLS gốc bị
sai. BбєЈng HC3 cung cấp SE Д‘ГЈ Д‘Ж°б»Јc hiệu chỉnh. Mб»Ќi kбєїt luбєn vб»Ѓ ГЅ nghД©a thб»‘ng
kГЄ phбєЈi dб»±a trГЄn bбєЈng nГ y. |
Diễn giải cụ thể:
•
BP_ (Brand Prestige): B = 0.386, SE robust = 0.083, t = 4.672,
p < .001, 95% CI [0.223; 0.549]. Khi BP_ tăng 1 đơn vị, WOM_ tăng trung bình
0.386 Д‘ЖЎn vб»‹, sau khi kiб»ѓm soГЎt PDS_. TГЎc Д‘б»™ng nГ y cГі ГЅ nghД©a thб»‘ng kГЄ.
•
PDS_ (Perceived Dependability & Service): B = 0.451, SE robust =
0.078, t = 5.806, p < .001, 95% CI [0.298; 0.604]. PDS_ cГі tГЎc Д‘б»™ng mбєЎnh hЖЎn
BP_ (hệ số lớn hơn và t-value lớn hơn).
• Intercept: B = 0.585, p = .066 > .05, khГґng cГі ГЅ nghД©a thб»‘ng kГЄ — Д‘iб»Ѓu nГ y bГ¬nh thЖ°б»ќng vГ Гt khi Д‘Ж°б»Јc quan tГўm trong nghiГЄn cб»©u б»©ng dụng.
6.
Lбєp bбєЈng bГЎo cГЎo hб»Ќc thuбєt chuбє©n APA
Bảng 1. Kiểm định phương sai sai số không đồng nhất và độ
phù hợp mô hình
|
Nб»™i dung |
GiГЎ trб»‹ |
Sig. |
|
Kiб»ѓm Д‘б»‹nh White |
П‡ВІ(5) = 45.222 |
<
.001 |
|
Modified Breusch–Pagan |
П‡ВІ(1) = 36.217 |
<
.001 |
|
Breusch–Pagan |
П‡ВІ(1) = 56.743 |
<
.001 |
|
F-test (heteroskedasticity) |
F(1,
268) = 41.518 |
<
.001 |
|
Mô hình tổng thể |
F(2,
267) = 120.424 |
<
.001 |
|
RВІ |
.474
(Adjusted RВІ = .470) |
|
|
N |
270 |
|
|
Ghi chú: Biến phụ thuộc: WOM_ (Word-of-Mouth). Biến
Д‘б»™c lбєp: BP_ (Brand Prestige) vГ PDS_ (Perceived Dependability &
Service). Kiểm định White và Breusch–Pagan kiểm tra H0: phương sai sai số
khГґng phụ thuб»™c vГ o cГЎc biбєїn Д‘б»™c lбєp. Tất cбєЈ cГЎc kiб»ѓm Д‘б»‹nh heteroskedasticity
đều có ý nghĩa thống kê (p < .001), cho thấy giả định phương sai đồng nhất
bị vi phạm. Do đó, các hệ số hồi quy được ước lượng với sai số chuẩn hiệu chỉnh
robust theo phЖ°ЖЎng phГЎp HC3 (MacKinnon & White, 1985). |
BбєЈng 2. Kбєїt quбєЈ Ж°б»›c lЖ°б»Јng hб»“i quy vб»›i Robust Standard
Errors (HC3)
|
Biбєїn |
B |
Robust SE (HC3) |
t |
p |
95% CI |
|
Intercept |
0.585 |
0.317 |
1.847 |
.066 |
[в€’0.039;
1.209] |
|
BP_ |
0.386 |
0.083 |
4.672 |
< .001 |
[0.223; 0.549] |
|
PDS_ |
0.451 |
0.078 |
5.806 |
< .001 |
[0.298; 0.604] |
|
Ghi chú: Biến phụ thuộc: WOM_ (Word-of-Mouth). N =
270. Sai số chuẩn được ước lượng theo phương pháp HC3 do phát hiện
heteroskedasticity. *p < .05, **p < .01, ***p < .001. |
BбєЈng 3. TГіm tбєЇt kбєїt quбєЈ kiб»ѓm Д‘б»‹nh giбєЈ thuyбєїt (tuб»і chб»Ќn)
|
GiбєЈ thuyбєїt |
Nб»™i dung |
B |
p |
Kбєїt quбєЈ |
|
H1 |
BP_
tГЎc Д‘б»™ng cГ№ng chiб»Ѓu Д‘бєїn WOM_ |
0.386 |
<
.001 |
Chấp
nhбєn |
|
H2 |
PDS_
tГЎc Д‘б»™ng cГ№ng chiб»Ѓu Д‘бєїn WOM_ |
0.451 |
<
.001 |
Chấp
nhбєn |
7.
Mбє«u viбєїt kбєїt quбєЈ theo vДѓn phong hб»Ќc thuбєt
7.1. TrЖ°б»ќng hб»Јp vi phбєЎm (cГі heteroskedasticity)
"MГґ
hình hồi quy kiểm tra tác động của BP_ và PDS_ lên WOM_ có ý nghĩa thống kê tổng
thб»ѓ, F(2, 267) = 120.424, p < .001, RВІ = .474, cho thấy hai biбєїn Д‘б»™c lбєp giбєЈi
thГch Д‘Ж°б»Јc 47.4% biбєїn thiГЄn của WOM_. NghiГЄn cб»©u kiб»ѓm tra giбєЈ Д‘б»‹nh phЖ°ЖЎng sai Д‘б»“ng
nhất bằng kiểm định Breusch–Pagan và White (Breusch & Pagan, 1979; White,
1980). Tất cả bốn kiểm định đều có ý nghĩa thống kê (White: χ²(5)
= 45.222, p < .001; Breusch–Pagan:
П‡ВІ(1) = 56.743, p < .001; Modified BP: П‡ВІ(1)
= 36.217, p < .001; F-test: F(1, 268) = 41.518, p < .001), cho thấy giả định
phương sai đồng nhất bị vi phạm. Do đó, các hệ số hồi quy được ước lượng sỠdụng
sai sб»‘ chuбє©n hiệu chỉnh robust theo phЖ°ЖЎng phГЎp HC3 Д‘б»ѓ Д‘бєЈm bбєЈo suy luбєn thб»‘ng
kГЄ Д‘ГЎng tin cбєy hЖЎn (MacKinnon & White, 1985)."
"Kбєїt quбєЈ Ж°б»›c lЖ°б»Јng vб»›i robust SE cho thấy BP_ cГі tГЎc Д‘б»™ng dЖ°ЖЎng vГ cГі ГЅ nghД©a thб»‘ng kГЄ Д‘бєїn WOM_ (B = 0.386, SE = 0.083, t = 4.672, p < .001, 95% CI [0.223; 0.549]). TЖ°ЖЎng tб»±, PDS_ cЕ©ng tГЎc Д‘б»™ng dЖ°ЖЎng vГ cГі ГЅ nghД©a thб»‘ng kГЄ Д‘бєїn WOM_ (B = 0.451, SE = 0.078, t = 5.806, p < .001, 95% CI [0.298; 0.604]). So sГЎnh hệ sб»‘ cho thấy PDS_ cГі tГЎc Д‘б»™ng mбєЎnh hЖЎn BP_ Д‘бєїn WOM_. NhЖ° vбєy, cбєЈ H1 vГ H2 Д‘б»Ѓu Д‘Ж°б»Јc ủng hб»™."
7.2. TrЖ°б»ќng hб»Јp khГґng vi phбєЎm (tham khбєЈo)
"Nghiên cứu kiểm tra giả định phương sai đồng nhất bằng kiểm định Breusch–Pagan và White (Breusch & Pagan, 1979; White, 1980). Các kiểm định không có ý nghĩa thống kê (p > .05), cho thấy chưa có bằng chứng về hiện tượng phương sai sai số không đồng nhất. Do đó, kết quả OLS tiêu chuẩn được sỠdụng để diễn giải."
8.
CГЎc lЖ°u ГЅ quan trб»Ќng vГ sai lбє§m thЖ°б»ќng gбє·p
8.1. Levene's test KHГ”NG phбєЈi lГ kiб»ѓm Д‘б»‹nh
heteroskedasticity trong hб»“i quy
Levene's test kiб»ѓm tra bбє±ng nhau
phương sai giữa các nhóm (dùng cho ANOVA, t-test). Breusch–Pagan và White
kiểm tra phương sai sai số thay đổi theo biến dự báo liên tục trong hồi quy.
Đây là hai khái niệm khác nhau hoà n toà n.
|
Sai lбє§m phб»• biбєїn: Nhiб»Ѓu nghiГЄn cб»©u sinh dГ№ng Levene's test Д‘б»ѓ kiб»ѓm
tra heteroskedasticity trong hồi quy — đây là sai về mặt phương pháp. Nếu biến
Д‘б»™c lбєp lГ liГЄn tục nhЖ° BP_, PDS_, chỉ Breusch–Pagan vГ White mб»›i phГ№ hб»Јp. |
8.2. CбєЈnh bГЎo "HOMOGENEITY will be ignored" lГ
bình thường
DГІng cбєЈnh bГЎo trong
SPSS: "The HOMOGENEITY specification in the PRINT subcommand will be
ignored because there are no between-subjects factors" xuất hiện khi
mô hình không có biến phân nhóm (Factor). Đây là bình thường và không ảnh hưởng
Д‘бєїn cГЎc kiб»ѓm Д‘б»‹nh White/BP.
8.3. NГЄn Д‘б»Ќc bбєЈng nГ o khi cГі robust SE? ***
|
Khi cГі heteroskedasticity |
BбєЈng NГЉN Д‘б»Ќc |
BбєЈng KHГ”NG nГЄn Д‘б»Ќc |
|
Hệ
sб»‘ vГ ГЅ nghД©a |
Parameter
Estimates with Robust SE (HC3) |
Tests
of Between-Subjects Effects (OLS) |
|
F
mô hình tổng thể |
Vбє«n
Д‘б»Ќc tб»« Tests of Between-Subjects Effects |
|
|
RВІ |
Vбє«n
Д‘б»Ќc tб»« Tests of Between-Subjects Effects |
|
8.4. LГ m trГІn sб»‘ vГ quy Ж°б»›c p-value theo APA
•
Hệ
sб»‘ B, SE: lГ m trГІn Д‘бєїn 3 chб»Ї sб»‘ thбєp phГўn
•
p-value:
viбєїt p < .001 (khГґng viбєїt p = .000)
•
Thб»‘ng
kГЄ t, F, П‡ВІ: lГ m
trГІn Д‘бєїn 3 chб»Ї sб»‘ thбєp phГўn
• Không viết giá trị p thực khi nó nhỏ hơn .001
9.
Quy trình khuyến nghị toà n diện
|
BЖ°б»›c |
HГ nh Д‘б»™ng |
Công cụ SPSS |
|
1 |
ChбєЎy
mГґ hГ¬nh hб»“i quy chГnh |
UNIANOVA
hoбє·c REGRESSION |
|
2 |
Xem
biб»ѓu Д‘б»“ phбє§n dЖ° sЖЎ bб»™ (ZPRED vs ZRESID) |
Graphs
в†’
Scatter/Dot |
|
3 |
ChбєЎy
kiб»ѓm Д‘б»‹nh Breusch–Pagan vГ White chГnh thб»©c |
/PRINT
WHITE BP MBP F trong UNIANOVA |
|
4a |
Nбєїu
p > .05: Дђб»Ќc kбєїt quбєЈ OLS tiГЄu chuбє©n |
Tests
of Between-Subjects Effects |
|
4b |
Nбєїu
p < .05: Chuyб»ѓn sang robust SE HC3 |
/ROBUST=HC3
trong UNIANOVA |
|
5 |
BГЎo
cГЎo: F, RВІ, cГЎc kiб»ѓm Д‘б»‹nh, B, robust SE, t, p, CI |
BбєЈng
bГЎo cГЎo hб»Ќc thuбєt |
Kбєїt
luбєn
Kiб»ѓm Д‘б»‹nh phЖ°ЖЎng sai
sai sб»‘ khГґng Д‘б»“ng nhất khГґng chỉ lГ thủ tục bбєЇt buб»™c trong phГўn tГch hб»“i quy
nghiêm túc, mà còn là tiêu chà ngà y cà ng được các hội đồng phản biện quốc tế
yêu cầu. Kết hợp kiểm định Breusch–Pagan và White với robust standard
errors HC3 — Д‘Гєng nhЖ° cГўu trГch dбє«n chuбє©n mб»±c "(Breusch &
Pagan, 1979; White, 1980; MacKinnon & White, 1985)" — là thực hà nh
tốt nhất hiện tại cho nghiên cứu định lượng trong khoa học xã hội.
Nбєїu bбєЎn cбє§n hб»— trб»Ј phГўn
tГch dб»Ї liệu hб»“i quy, kiб»ѓm Д‘б»‹nh heteroskedasticity, hoбє·c viбєїt bГЎo cГЎo kбєїt quбєЈ
cho luбєn vДѓn vГ bГ i bГЎo khoa hб»Ќc, cГі thб»ѓ liГЄn hệ vб»›i chГєng tГґi Д‘б»ѓ Д‘Ж°б»Јc tЖ° vấn.
Tà i liệu tham khảo
Breusch, T. S., &
Pagan, A. R. (1979). A simple test for heteroscedasticity and random
coefficient variation. Econometrica, 47(5), 1287–1294.
Hair, J. F., Black, W.
C., Babin, B. J., & Anderson, R. E. (2019). Multivariate Data Analysis
(8th ed.). Cengage Learning.
MacKinnon, J. G., &
White, H. (1985). Some heteroskedasticity-consistent covariance matrix
estimators with improved finite sample properties. Journal of Econometrics,
29(3), 305–325.
White, H. (1980). A heteroskedasticity-consistent covariance matrix estimator and a direct test for heteroskedasticity. Econometrica, 48(4), 817–838.
Nếu đọc giả muốn tham khảo tà i liệu trong nước (tiếng Việt), bạn đọc có thể tham khảo cuốn Mô hình hồi quy và Khám phá khoa học của tác giả GS. Nguyễn Văn Tuấn
Nếu đọc giả muốn tham khảo các ấn bản quốc tế, chúng tôi xin phép được giới thiệu 2 cuốn sách khá hay là "Introduction to Business Analytics Using Simulation" của Pinder, Jonathan P. (2023) và "Introduction to Robust Estimation and Hypothesis Testing" của Rand R. Wilcox (2022)


BГ i Viбєїt LiГЄn Quan.



